
Python for Data Mining
سرفصل و محتوای آموزش Python for Data Mining
مدت دوره: 44 ساعت
پیشنیاز دوره: آشنایی با مفاهیم برنامه نویسی و بانک های اطلاعاتی
مخاطبین دوره: مهندسان و دانشمندان و تمام علاقه مندان به حوزه علوم داده و داده کاوی
معرفی دوره:
امروزه استخراج دانش و کشف الگوها و مفاهیم پنهان از داده ها نقش به سزایی در پیشرفت کسب و کارها پیدا کرده است. زبان برنامه نویسی پایتون (Python) نیز یکی از محبوبترین و متداول ترین ابزارهای موجود برای استخراج دانش از داده هاست.
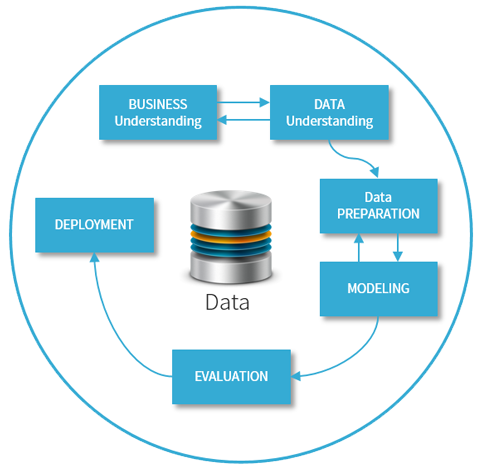
در این دوره مفاهیم داده کاوی، الگوریتمها و روشها به صورت تئوری مطرح میشود. سپس طبق فرایند CRISP مراحل مختلف انجام یک پروژه داده کاوی در پایتون (Python) به صورت عملی و کاربردی آموزش داده می شود.
مشاهده ی رزومه استاد دوره
سرفصل دوره:
مقدمه ای بر برنامه نویسی در پایتون
- نصب پایتون و پکیج های مرتبط
- انواع داده ها
- انواع عملگرها
- ساختارهای کنترلی
- توابع
مفاهیم و مبانی داده کاوی
- مقدمه ای بر داده کاوی
- درک، پاکسازی و پیش پردازش داده ها
- مدلسازی
الگوریتم های رده بندی ( Classification Algorithms)
الگوریتم های رگرسیون (Regression Algorithms)
الگوریتم های خوشه بندی (Clustering Algorithms)
الگوریتم های کشف الگوهای مکرر و قواعد انجمنی (Frequent Patterns & Association Rules Mining Algorithms)
روش های یادگیری جمعی
- آشنایی با روش های مختلف ارزیابی مدل ها
پیاده سازی مراحل داده کاوی در پایتون
- پیش پردازش داده ها (Data Pre-processing)
- رده بندی و رگرسیون (Classification and Regression)
درخت تصمیم (Decision Tree)
بیز ساده (Naïve Bayes)
شبکه عصبی پرسپترون چند لایه (Multi Layer Perceptron)
ماشین بردار پشتیبان (Support Vector Machine)
نزدیکترین همسایگی (K-Nearest Neighbors)
رگرسیون خطی (Linear Regression)
رگرسیون لجستیک (Logistic Regression)
روش های یادگیری تجمعی (Ensemble Learning)
- خوشه بندی (Clustering)
الگوریتم K-means
الگوریتم DBSCAN
- کشف الگوهای مکرر و قواعد انجمنی
الگوریتم Apriori
الگوریتم Fp-frowth
- روش های ارزیابی مدلها (Evaluation)
ارزیابی مدلهای رده بندی
ارزیابی مدلهای رگرسیون
ارزیابی مدلهای خوشه بندی
ارزیابی الگوهای پرتکرار و قواعد انجمنی
روش های تجمیعی در داده کاوی (Ensemble methods)
o روش های پایه (Basic methods)
o Bagging
o Boosting
o Stacking
o XGBoost
o LightGBM
o CatBoost
مهندسی ویژگی ها (Feature Engineering)
o انواع روش های ساخت ویژگی های جدید (Feature Creation)
o روش های متداول و به روز در انتخاب ویژگی ها (Feature Subset Selection)
دسترسی سریع
تماس با فراتر از دانش
آدرس: تهران - کارگر شمالی - بالاتر از چهار راه فاطمی (ایستگاه مترو کارگر) - کوچه دیدگاه - پلاک 26 - طبقه 3 شرکت فراتر از دانش
تلفن : 02188989781 - 02188989782
واتس اپ : 09396839678
فکس : 02188989780
- ایمیل: info@fad.ir

